
 yqk 勾引
yqk 勾引
本文由半导体产业纵横(ID:ICVIEWS)编译自tomshardware
英伟达通过销售H20,赚了数百亿好意思元。
英伟达在 2023 年和 2024 年的飙升成绩于东说念主工智能范围对 GPU 的爆炸性需求,主若是在好意思国、中东国度和中国。
为了将AI GPU加快器卖给中国,NVIDIA接连打造了多款缩水的特供版,从早期的A800、H800到其后的H20、L20、L2。
其中,H20是最让中国客户惬意的,因为它基于新的Hopper架构,主要作念训导(L20/L2皆是中国不太需要的Ada架构推理卡),销量亦然节节攀升。
由于好意思国存在出口律例,何况英伟达无法在莫得政府出口许可的情况下将其最高端的 Hopper H100、H200 和 H800 处理器出售给中国,因此它转而将其削减版的HGX H20 GPU 出售给中国实体。
然而,分析师Claus Aasholm示意,尽管削减了,但 HGX H20 的销售施展却极端出色。
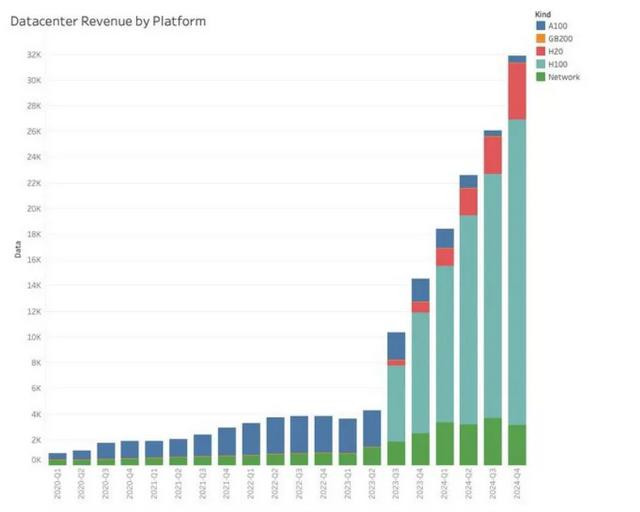
Aasholm 写说念:“通过了中国禁令的左迁版 H20 系统施展稀疏好,环比增长 50%,这是英伟达最奏凯的产物。H100 业务仅环比增长 25%。”
凭据 Claus Aasholm 的发现,尽管 HGX H20 GPU 的性能与熟识的 H100 比拟大幅下跌,但英伟达仍通过销售该 GPU 赚取了数百亿好意思元。东说念主工智能如实是鼓励的确总共类型的数据中心硬件销售的大趋势,包括英伟达的 Hopper GPU,包括 HGX H20。
宇宙主要经济体——好意思国和中国——正在竞相取得最大的东说念主工智能智商。关于好意思国来说,增长或多或少是当然而然的:更多的资金和更多的硬件就是更高的智商,但这还不够。OpenAI 本身就赚了数十亿好意思元,但它需要更多的钱来取得更多的硬件,从而取得东说念主工智能训导和推聪慧商。
尽管存在种种律例,但中国的东说念主工智能智商(无论是硬件如故大型模子开辟)仍在握住扩大。就在上周,中国东说念主工智能公司 Deepseek 在一篇论文中泄露,它也曾在 2,048 个英伟达H800 GPU 集群上训导了其 6710 亿参数的 DeepSeek-V3 搀和民众 (MoE) 言语模子,耗时两个月,预计 280 万个 GPU 小时。
比拟之下,Meta 参加了 11 倍的计算资源(3080 万个 GPU 小时)来训导领有 4050 亿个参数的 Llama 3,耗时 54 天,使用了 16,384 个 H100 GPU。
跟着时辰的推移yqk 勾引,中国脉土的 Biren Technologies 和 Moore Threads 等公司推出的加快器可能会蚕食英伟达当前在中国数据中心的近乎驾驭地位。然而,这不能能一蹴而就。
英伟达年终大礼,最强AI GPU曝光
凭据SemiAnalysis的最新爆料,B300 GPU对计算芯片的想象进行了优化,并采取了全新的TSMC 4NP工艺节点进行流片。
比拟于B200,其性能的擢升主要在以下两个方面:
1. 算力
FLOPS性能擢升50%
功耗增多200W(GB300和B300 HGX的TDP折柳达到1.4KW和1.2KW;前代则为1.2KW和1KW)
架构变嫌和系统级增强,举例CPU和GPU之间的动态功率分派(power sloshing)
2. 内存
HBM容量增多50%,从192GB擢升至288GB
堆叠有盘算从8层HBM3E升级为12层
针脚速率保抓不变,带宽仍为8TB/s
序列长度的增多,导致KV Cache也随之扩大,从而律例了枢纽批处理大小和延长。
因此,显存的变嫌关于OpenAI o3这类大模子的训导和推理至关紧迫。
下图展示了英伟达H100和H200在处理1,000个输入token和19,000个输出token时的效用擢升,这与OpenAI的o1和o3模子中的念念维链(CoT)样式雷同。
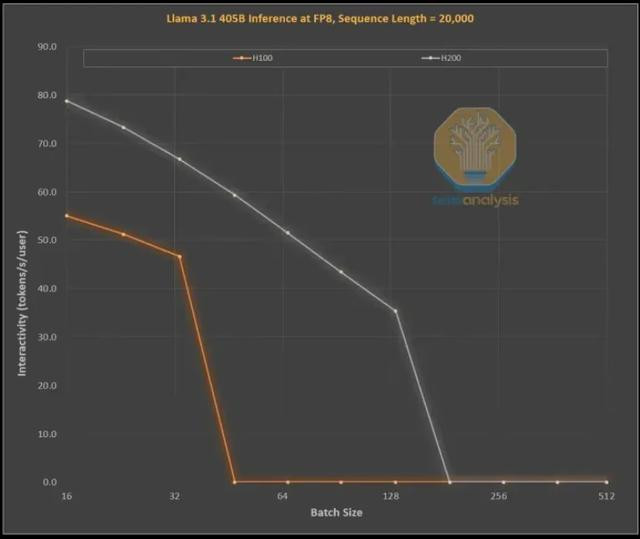
H100到H200的升级,主要在于更大、更快的显存:
更高的带宽使交互性能大量擢升了43%(H200为4.8TB/s,而H100为3.35TB/s)
日本乱伦更大的批处理范围,使每秒token生成量擢升了3倍,进而使本钱也裁减了约3倍
而对运营商而言,这H100和H200之间的性能与经济互异,远远卓越技能参数的数字那么简便。
来源,此前的推理模子正常因央求反当令辰长而影响体验,而当前有了更快的推理速率后,用户的使宅心愿和付费倾向皆将显赫提高。
其次,本钱裁减3倍的效益,然而极为可不雅的。仅通过中期显存升级,硬件就能终了3倍性能擢升,这种打破性进展远远卓越了摩尔定律、黄氏定律或任何已知的硬件跳跃速率。
临了,性能最顶尖、具有显赫互异化上风的模子,能因此取得更高溢价。
SOTA模子的毛利率也曾卓越70%,而濒临开源竞争的次级模子利润率仅有20%以下。推理模子可打破单一念念维链律例,通过膨大搜索功能擢升性能(如o1 Pro和o3),从而使模子更智能地惩处问题,提高GPU收益。
SemiAnalysis 示意,英伟达探究来岁推出的 B300 Tensor Core GPU 对想象进行了调治,将在台积电 4NP 定制节点上重新流片,合座来看可较 B200 GPU 擢升 50% 算力。
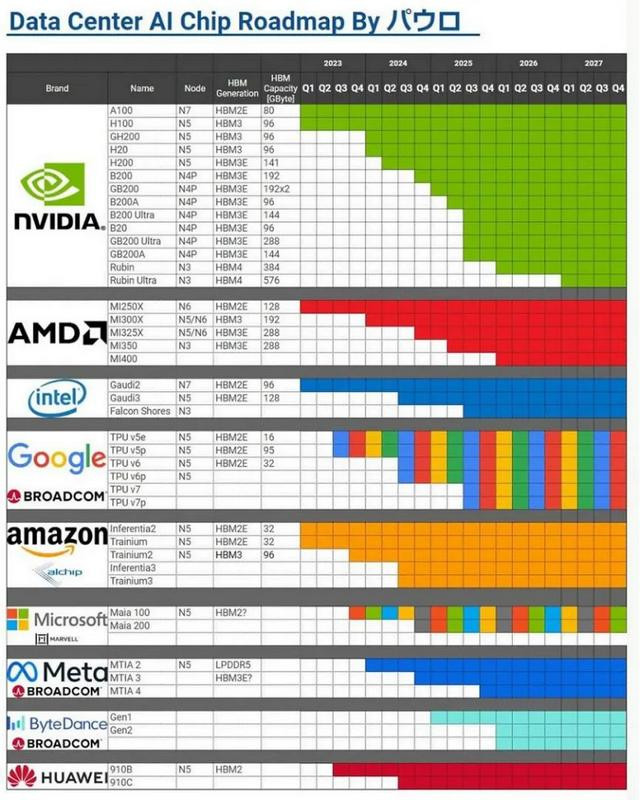
经济日报发布博文,英伟达(Nvidia)联袂台积电(TSMC)等供应链相助伙伴,为欢迎新一轮 AI 激越,同期亦然为矜重其在 AI 范围的来源地位,已提前起先下一代 Rubin 平台研发职责,原定 2026 年亮相的芯片有望提前 6 个月推出。
Rubin 是继 Blackwell 之后的下一代 AI GPU 架构,原探究于 2026 年发布,最新音问称将提前至 2025 年下半年,将采取台积电 3nm 工艺和下一代 HBM4 显存,大幅擢升 AI 计算性能。
音问称英伟达正与供应链相助伙伴致密相助,共同开辟基于 R100 的 AI 奇迹器,与此同期台积电探究扩大 CoWoS 先进封装产能,以舒适 Rubin 芯片的预期需求,看法是在 2025 年第四季度将 CoWoS 月产能擢升至 8 万片。
*声明:本文系原作家创作。著作践诺系其个东说念主不雅点yqk 勾引,本身转载仅为共享与征询,不代表本身赞颂或招供,如有异议,请关连后台。